Manually transcribing it can be tedious and time-consuming. However if you are on right system (Pop OS in this case), with the power of automation and the right tools, you can streamline this process and save yourself valuable time.
In this article, I'll share with you how I created a simple yet effective script using Tesseract OCR (Optical Character Recognition) and Gnome Screenshot to extract text from any region of the screen and copy it to the clipboard. Let's dive in!
Before we get started, it's important to note that you'll need to have both Gnome Screenshot and Tesseract installed on your system. These tools are readily available on most Linux distributions and can be easily installed using your package manager of choice. Once you have them installed, you're ready to proceed.
The script I've crafted combines the functionalities of Gnome Screenshot and Tesseract to capture a selected area of the screen, extract the text from it, and copy it to the clipboard. Here's a breakdown of what each part of the script does:
#!/bin/bash
# Create a temporary directory
TMPDIR=$(mktemp -d)
# Take a screenshot of a selected area and save it as screenshot.png in the temporary directory
gnome-screenshot -a -f $TMPDIR/screenshot.png
# Process the screenshot with Tesseract and save the result to a text file in the temporary directory
tesseract $TMPDIR/screenshot.png $TMPDIR/output
# Copy the result to the clipboard
# ignore all non-ASCII characters
cat $TMPDIR/output.txt |
tr -cd '\11\12\15\40-\176' | grep . | perl -pe 'chomp if eof' |
xclip -selection clipboard
# Optionally, remove the temporary directory when done
rm -r $TMPDIR
The script starts by creating a temporary directory to store the screenshot and its processed output. It then uses Gnome Screenshot to capture a selected area of the screen and save it as "screenshot.png" in the temporary directory.
Next, the script utilizes Tesseract to process the screenshot and extract any text present in it. The extracted text is saved to a file named "output.txt" in the same temporary directory.
The script then cleans up the extracted text, removing any non-ASCII characters, and copies it to the clipboard using the xclip command.
Finally, the temporary directory is removed to tidy up after the process is complete.
Personally I made this script runable by using chmod +x screenshot_to_clipboard.sh. Then I added ti to /usr/local/bin/screenshot_to_clipboard.sh so it is available to all users terminals. Also I did added keyboard shortcut to Ctrl+Q using GUI settings on PosOS but it should be straight forward for all gnome based systems.
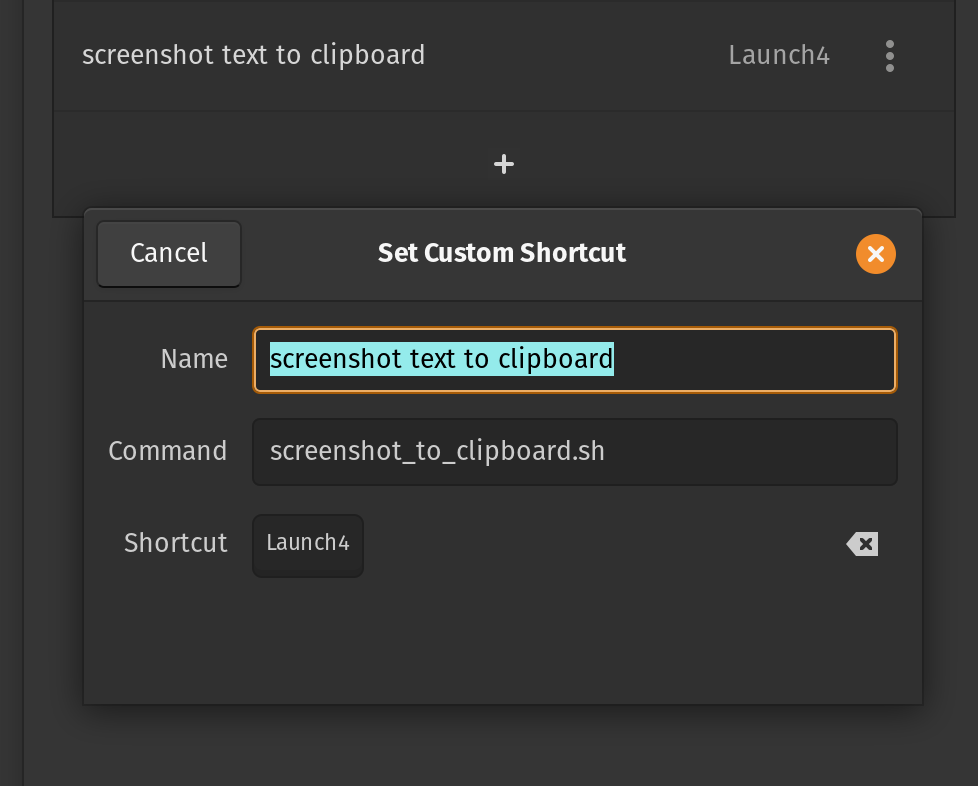
The process of using it is fairly straight forward, you click shortcut, the area selector is automatically initiated, when you select the area all readable text is copied to clipboard, the script is over and you can continue using your computer normally.
With the Tesseract OCR and Gnome Screenshot combo, extracting text from images or screenshots is a breeze! This script isn't just simple it's customizable too. Set it up once, hit a shortcut, and boom! Text is in your clipboard, ready to go. It's like magic for your productivity! 🚀

Thanks for reading! ^_^