I have been in the IT industry long enough to feel that projects rarely go according to schedule.
At first, I was in teams of young people with little to no experience. We did our jobs as best we could, but we missed our deadlines from time to time. We did all the engineering beforehand to give the best possible estimates with some buffer, but again we were wrong almost as much as we were when we were just eyeballing it.
Then I moved on to some more advanced projects, organizations, and teams. I also gained more experience, but still, the pattern continued. I was unhappy about it, I thought that I was a terrible engineer, and managers were unhappy from time to time.
My first line of defense was the thought that the software base we built on top of was bad, so we were struggling to fix the mess beneath our app layer, and that was the reason we frequently missed our deadlines.
My second phase was the belief that people are not suited to do programming, but by some miracle, we managed to do it anyway. So, I felt pretty good when we made something work.
Years passed, and I changed teams and talked to many people, but the pattern emerged everywhere. So, I started to suspect that it is not that simple. We can't just make up a story and call it a day, feeling good about our failure to meet deadlines. I owed it to myself to think of something better, so I did.
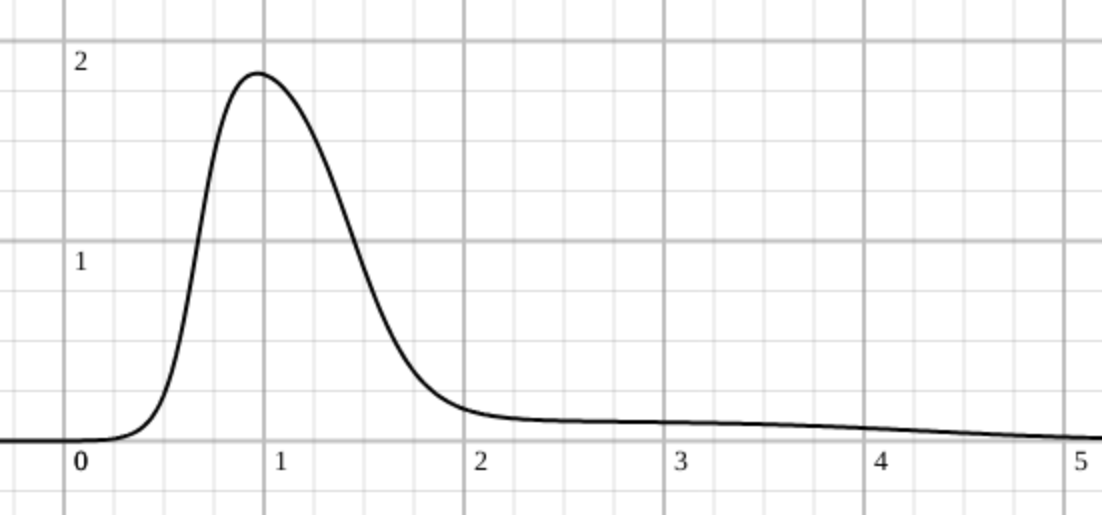
In words, it goes something like this: When doing one task, it is pretty probable for it to be done somewhere around the standard deviation of the estimate, and that task goes pretty well. I view it as a probability density function to finish a task in any given moment, I am not a mathematician, so excuse my crudeness. But when a task goes wrong, when we get out of that nice and safe zone, we have a low chance to finish it at any of the next moments. Imagine a Gaussian distribution, but it has a tail that is very thin. There is a low chance of getting into that tail because there is much more surface before that, so our minds ignore it, and managers do too.
My defense against that case was to give overestimates, and most people also do it, so our guess is always on the right side of the median, but regularly we finished our tasks on time, meaning early by our estimate. The reaction of management was that we were pressured to keep it real. But then, from time to time, there was a task or maybe a few that made everyone unhappy. We felt hopeless, missed deadlines even four times the estimate, and sometimes had to reorganize and redo the whole thing again.
Still, when we look at one task at a time, it is not all that grim. There is a slight chance that we make a mistake, but with more work, it will get fixed. We are humans, and we can do one thing at a time, so let's assume that ideally we finish one thing and then move on to another. It turns out that we get into that unpleasant situation more frequently than we intuitively felt we should. It makes us doubt our path in software engineering. I can't feel bummed forever about such feelings, so I started making an excuse that when we combine multiple Gaussian distributions with that tiny tail, it grows. But I did not have time to sit down and do the homework, so I made my best predictions and moved on with my life.
Recently, I was in a release situation that is still ongoing, and the feeling came back. So, I decided to do the work to get that thing calculated with my limited and rusted math knowledge.
The standard software procedure is if you can't define a thing well, you make a discrete approximation and grind numbers through a few for loops until you get integration, function product, or something you can't define but seems logical. In my mind, it's the same as simulation.
So, the distribution approximation I came up with is:
function trail(x) {
return Math.tanh(x*6-4) + Math.tanh(-x*3+4.3) * (1-trailProb) + Math.tanh(-x+4.3) * trailProb
}
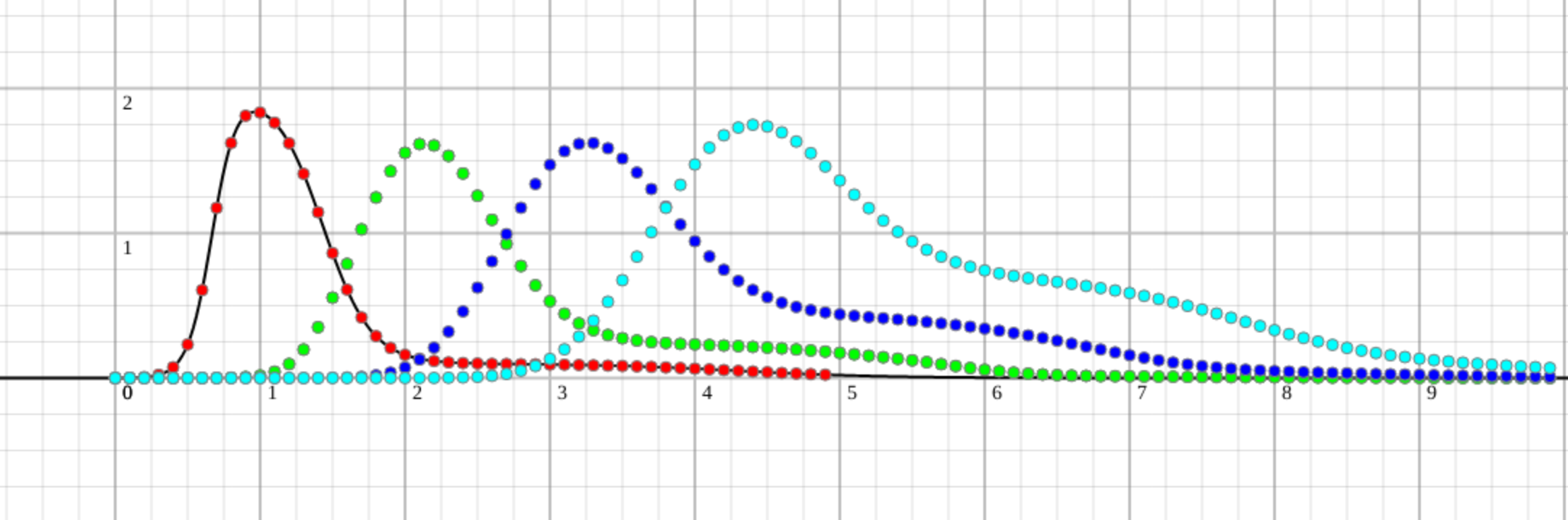
It is not pretty, but it gives the top figure. The idea of using the hyperbolic tangent function came from an AI course for perception, where it is used as a quick fix for the Sigmoid function.
Then I made it discrete like this:
let oneTask = {}
for(let i = 0; i < 200; i++){
oneTask[i] = trail(i/10)
}
I had a relative probability of finishing a task every 10% of a time estimate. It looks like this:
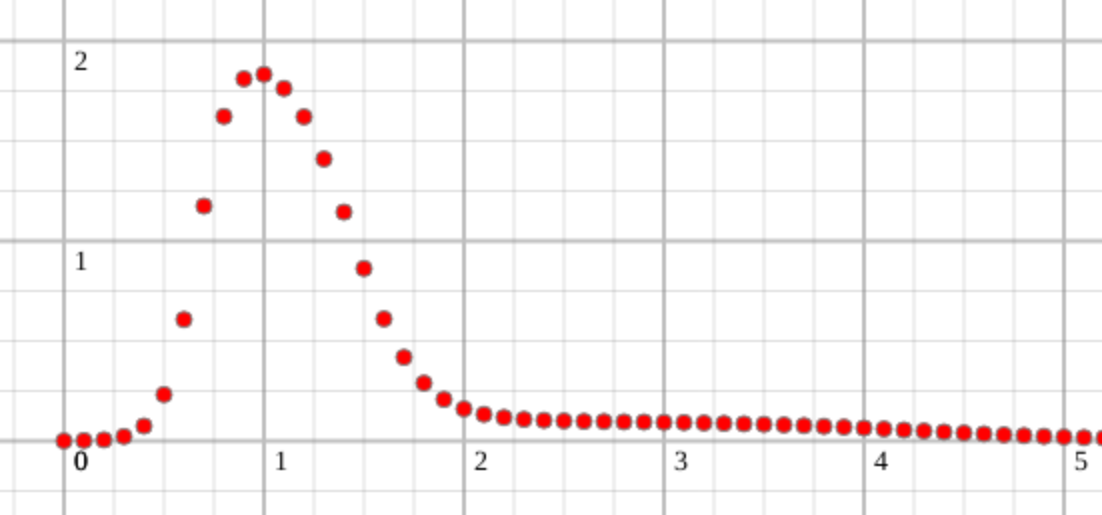
Then I had to come up with a way to combine tasks. Good thing it was discreet so I could reason about it and calculate it:
combineTwoTasks(task1, task2) {
let twoTasks = {}
for(let i = 0; i < 100; i++){
for(let j = 0; j < 200; j++){
let y1 = task1[i]
let y2 = task2[j]
let finalx = i+j
let finaly = y1*y2/DEVIDEER
twoTasks[finalx] = twoTasks[finalx] ? twoTasks[finalx] + finaly: finaly
}
}
return twoTasks
}
So, the x position is the added time of finishing the first task and the added time of finishing the second task, and the probability is the product of those two probabilities. Basically, it boils down to getting the sum of 7 when tossing two consecutive dice. In the end, you get all the ways you can finish at some moment. So, two tasks combined give another probability curve, going once again, you get 3 tasks, and so on.
So the whole code looks like this:
let oneTask = {}
for(let i = 0; i < 200; i++){
oneTask[i] = trail(i/10)
}
let twoTasks = this.combineTwoTasks(oneTask, oneTask)
let threeTasks = this.combineTwoTasks(oneTask, twoTasks)
let nTasks = oneTask
for(let i = 0; i < 7; i++){
nTasks = this.combineTwoTasks(oneTask, nTasks)
}
for(let i = 0; i < 200; i++){
this.addPoint(i/10, -oneTask[i]||0)
this.addPoint(i/10, -twoTasks[i]||0, '#00ff00')
this.addPoint(i/10, -threeTasks[i]||0, '#0000ff')
this.addPoint(i/10, -nTasks[i]||0, '#00ffff')
}
For the first few tasks, the time and probability of finishing look like this:
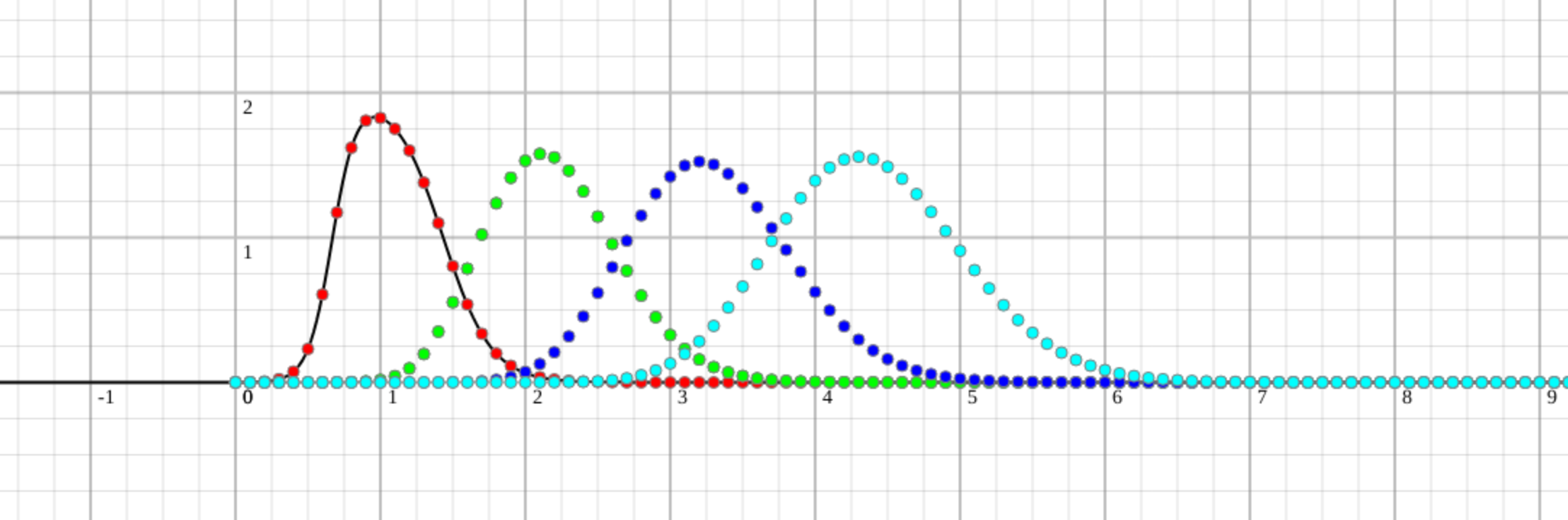
And it looks fine. We should be ashamed to do all this work and get a result that throws a wet towel in our faces and says we are all bad developers. But this is when all the variables are known when there is no unknown thing that can make that tedious tail. When we raise the chance to get into that awkward situation just a little bit, the results are a bit different:
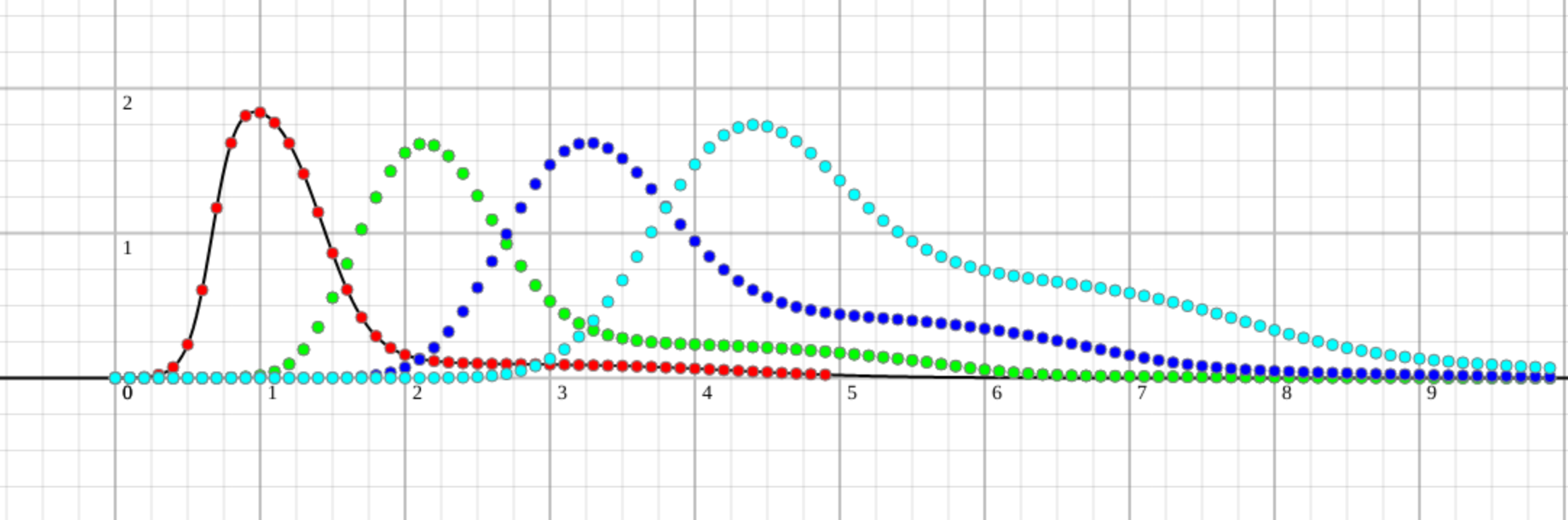
We see that a small tail of a task that is barely perceivable can impact us on the fourth task destructively. Something like barely 1-2% of the area under the curve becomes 20%-30%, and that is only for 4 tasks with an almost sure outcome. We have almost no chance to finish on time (<10%) and a good chance to overdo it by 1.5x of the original guesstimate. 2x is not far-fetched either.
I wanted to play a little bit and see 7 sequential tasks:
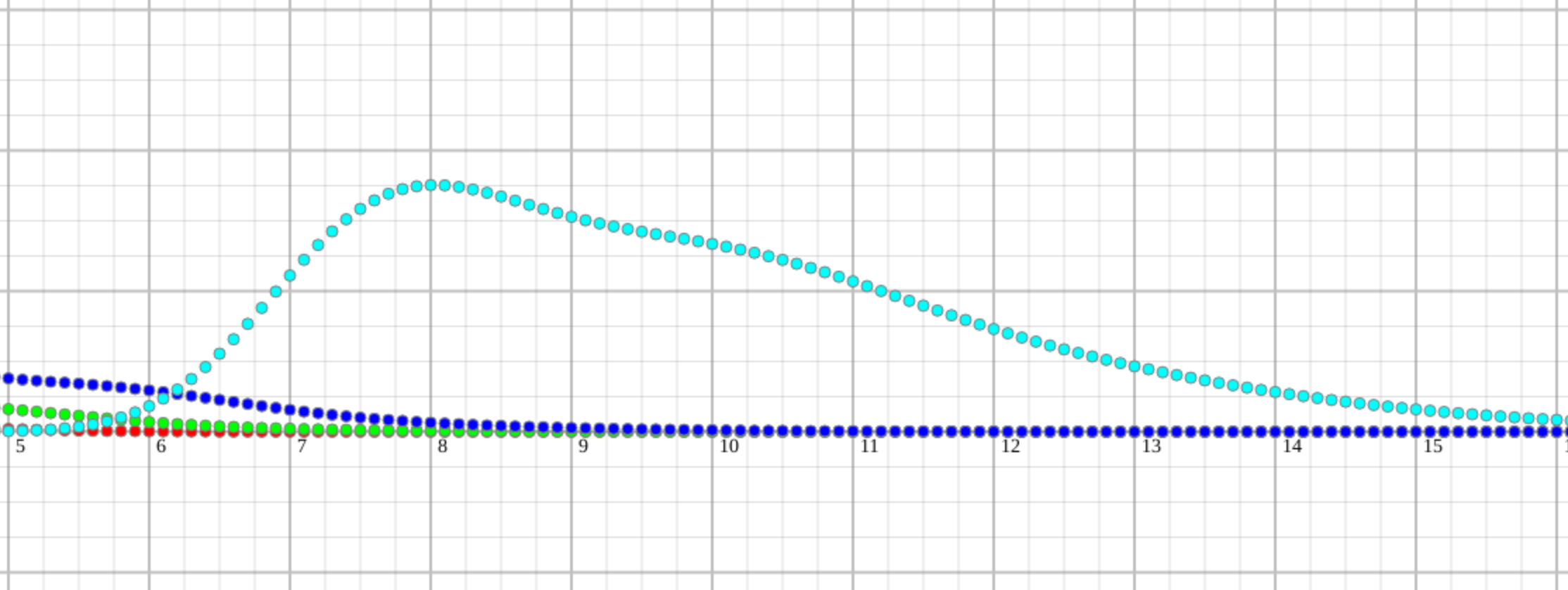
The story continues, we should be done by 7, we are probably doing it by 9.5 estimates, and we have the same chance to finish after 13 estimates as we do to finish on time.
There are a lot of tasks that have much bigger tail sections due to various reasons. Only the tasks where all the variables are known and are in the pure Gaussian distribution form can be estimated and delivered repeatedly and reliably.
I hope this helps fellow developers not to feel bad when things go wrong. It is the nature of the universe and helps organizations and managers adapt to the truth.
You can check my few hours of coding mess here: Github source

Thanks for reading! ^_^